 This is the third post in a series exploring how scientific software companies might be able to make money while still keeping their code open. The previous articles are:
This is the third post in a series exploring how scientific software companies might be able to make money while still keeping their code open. The previous articles are:
There’s also a related thread going on at Notes from the Biomass.
The point of these articles is to find a way for producers of good scientific software to make money while still keeping their codes open for skeptical review. I think it is good scientific practice that codes be open to review, but I’m also sympathetic with the desire of the developers of this software to put food on the table.
One of the more common business models in the open source community that produces commodity software (e.g. operating systems) is to sell services. There are many examples of companies that provide source-level and binary downloads of one version of their product, while charging for the “enterprise” or supported version. The canonical example of this is RedHat, and judging from much of the chatter on the various scientific mailing lists (e.g. ccl.net), enterprise-level support for some of the major computational chemistry packages is sorely lacking. There’s clearly a demand for scientific software support, but would a support-based system be a viable way to support a company that opens up its code?
Again, the economics seems stacked against this model. First, scientific software targets a relatively small group of users, and at the same time, the development and support costs are often quite large. Problems with the software are often so complex they can’t be addressed by online FAQs or with banks of inexpensive support staff. So the support contracts would need to be expensive.
Secondly, academic users of scientific software have pools of relatively cheap but intelligent and highly-skilled labor. Why would a researcher spend $10000 on a support contract if the problem could be solved by throwing a graduate student at the open source version of the code for a few months?
The entire expense of the software development and support services would then fall on the few corporate clients of the producer of the software. Simply dividing the costs to the company by the number of expected buyers of the software means the initial price of a license or support contract would be prohibitively high, and if the software was high-quality software, I would expect that some of the corporate clients would attempt to run with the source just like the academics would.
For this reason, I’m reasonably sure that “selling support” isn’t a viable model for the scientific software community to adopt.
However, there is another way to sell services. Suppose a given software company acted as a service bureau that performed a specific kind of calculation for industry and academic labs. That is, if a company was producing an open source ligand docking program, they could supply the service of screening a particular set of potential drug molecules against a specific binding domain on a known protein target. The cost to provide data for one molecule docking with a binding domain could then be set reasonably low so that academic researchers could become familiar with the service. Clients that had larger demands (i.e. pharmaceutical companies) could subscribe to this service for an annual fee.
Essentially, this model has the company that wrote a piece of open source scientific software acting as a single-purpose supercomputing center. Since the developers of the primary application would be on staff, the company would already have the scientific and computational expertise to run the service. All that would be required would be clients willing to submit their “jobs” to the service bureau.
Would this model work in all scientific fields? Probably not. The company would need industrial clients with relatively deep pockets and a need for their services. But in chemistry, at least, the trend has been for the fine chemical and pharmaceutical companies to scale down their in-house computational groups. Would they be willing to farm-out their computational tasks to another company, particularly when the relevant information (like drug leads or even the targets of those drug molecules) are trade secrets? I don’t know yet, but I’m not aware of anyone who has tried this approach.
So my conclusions thus far are that “sell hardware” and “sell support” won’t work to fund open source science software, but there might find some scientific fields where computational service bureaus spring up around a piece of open source code.
Next up: Dual Licensing

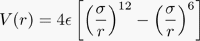
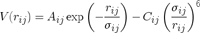

{kind=link}